Some of the recent image-generating models have this thing where they can fill in the blank parts of images. It's handy when you want to show them exactly how to give you more of the same. Like these animal emoji. See if you can tell which ones I
One of the things I'm enjoying about text-to-image generators like DALL-E2 is
how it has stuff about common brands in its training data, but it still manages
to completely garble them
[https://www.aiweirdness.com/ai-versus-your-corporate-logo/].
Please enjoy these DALL-E2 attempts at Halloween candy favorites.
Prompt: "Product
Recently I've been experimenting with DALL-E 2, one of the models that uses CLIP
to generate images from my text descriptions. It was trained on internet text
and images, so there's a lot it can do, and a lot of ways it can remix the stuff
One thing I've noticed with image-generating algorithms is that the more of
something they have to put in an image, the worse it is.
I first noticed this with the kitten-generating variant of StyleGAN, which often
does okay on one cat:
alternative for shocked_pikachu.pngbut is terrible
DALL-E (and other text-to-image generators) will often add text to their images
even when you don't ask for any. Ask for a picture of a Halifax Pier
[https://www.aiweirdness.com/the-terror-of-the-sea/] and it could end up covered
in messy writing, variously legible versions of "Halifax"
I recently started playing with DALL-E 2, which will attempt to generate an
image to go with whatever text prompt you give it. Like its predecessor DALL-E,
it uses CLIP, which OpenAI trained on a huge collection of internet images and
nearby text. I've experimented with a few
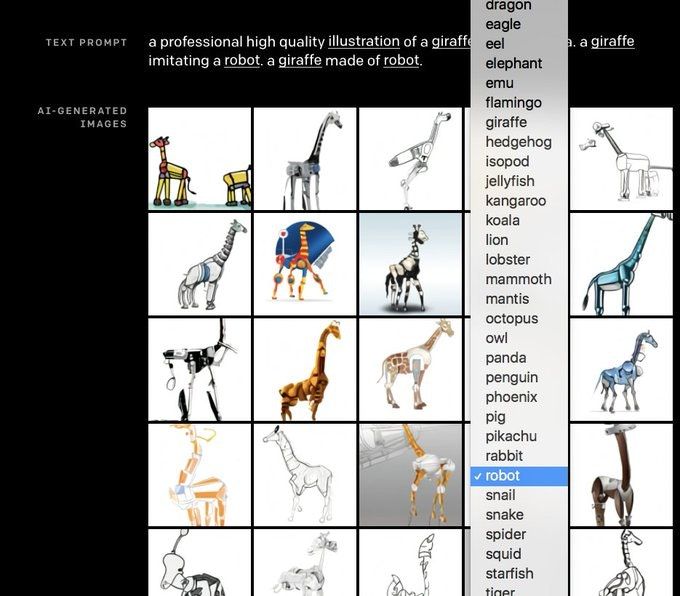
What type of giraffe would you like today?
Last week OpenAI published a blog post previewing DALL-E
[https://openai.com/blog/dall-e/], a new neural network that they trained to
generate pictures from text descriptions. I’ve written about past algorithms
that have tried to make drawings to order
[https: